
Scaling Microservices Part 7 - Faster Reads With a Separate Read Model Using CQRS
Reading data can be slow in systems with complex domain models. Various solutions can help improve performance. In this article, we'll explore how Command Query Responsibility Segregation (CQRS) can optimize data retrieval.
What is CQRS?
CQRS is a design pattern where the public API of the system is divided into two separate parts:
- Commands: Operations that perform actions that write data. While commands may internally read data, their primary responsibility is to make changes.
- Queries: Operations that read and return data. They should not modify data.
This separation ensures clear responsibilities: commands write data, and queries read data.
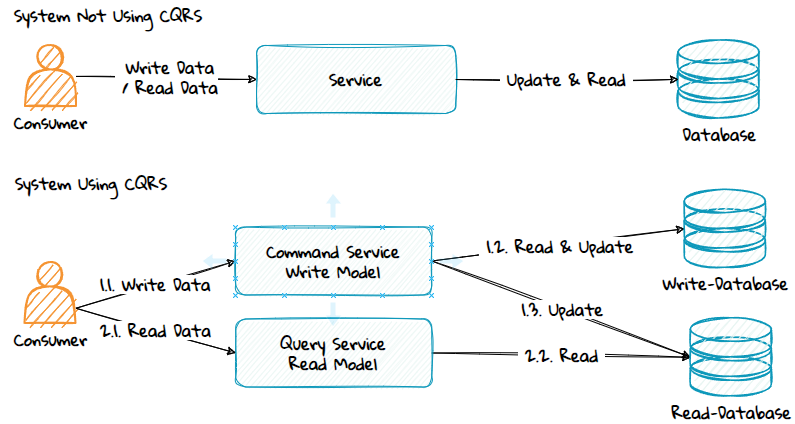
In a CQRS architecture:
- Commands write data to a write-database which can be an RDBMS.
- The system creates or updates an optimized, denormalized, projected version of the data in a read-database. The read-database can be an RDBMS, a document database, or any other NoSQL database.
- Query operations retrieve data directly from the read-database, avoiding complex queries or aggregations.
- The read-database stores data in a format close to how it will be consumed, making retrieval faster and more efficient.
Advantages of CQRS
- Improved performance: The query side uses a read-optimized model for fast data retrieval, this gives faster response times and reduces resource usage.
- Flexible and cost-effective scaling: The read-database can be scaled independently of the write-database, either vertically or horizontally.
- Improved security: Query operations only need access to the read-database.
Disadvantages of CQRS (Depends on Implementation)
- Increased complexity and higher maintenance cost: Developers must understand, develop and maintain two models.
- Risk of inconsistency: The read model can become permanently out of sync with the write model unless appropriate preventive measures are implemented.
- Eventual consistency: There may be a delay between when the write-database is updated and when the read-database is updated.
- Difficult error handling: Debugging issues across multiple databases, or services can be challenging.
CQRS Variations
As with many architectural patterns, CQRS exists in many forms and variations. You can tailor it based on your requirements:
- Good enough performance vs great performance.
- Strict data integrity vs acceptable levels of inconsistency.
- Eventual consistency vs immediate consistency.
- Simplicity vs high complexity.
Below are some common approaches to implementing CQRS.
1. Single Service for Both Command and Query
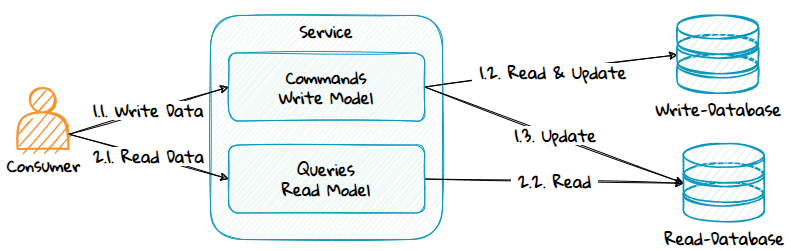
Advantages:
- A single service to create, deploy, and manage.
- Cost-effective.
Disadvantages:
- Commands and queries cannot scale independently.
- A single security context, the commands and queries share the same permissions.
2. Separate Command Service and Query Service
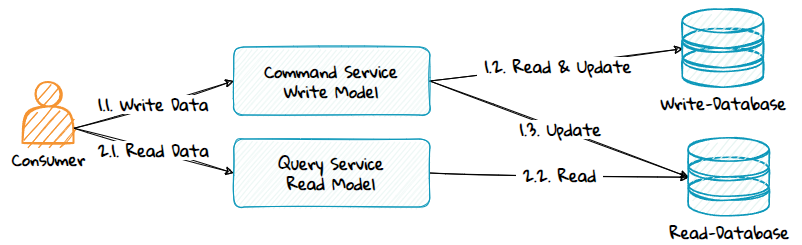
Advantages:
- Commands and queries can scale independently.
- Different security contexts for commands and queries, enabling stricter access control.
Disadvantages:
- Two services to create, deploy, and manage.
- Potentially higher infrastructure costs.
3. Same Database for the Read and Write Model
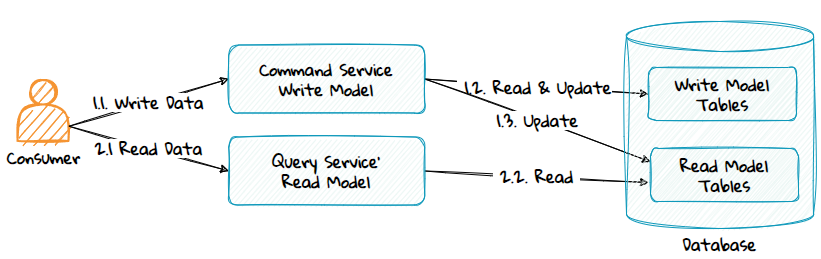
Advantages:
- Local transactions ensure data consistency between the write and read models.
Disadvantages:
- The read-database cannot scale independently of the write-database.
4. Different Databases for the Read and Write Model
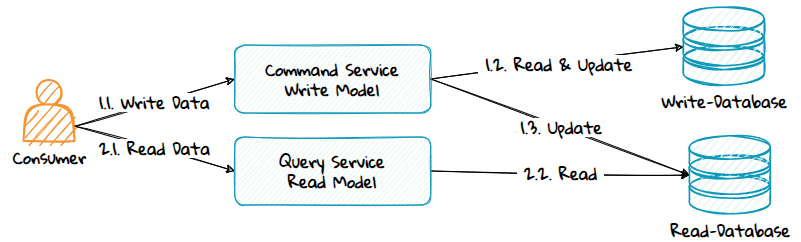
Advantages:
- The read database can scale independently of the write database.
- Different database technologies can be used for write and read models, e.g. RDBMS for writes, NoSQL for reads.
Disadvantages:
- Risk of data inconsistency if a command fails. The write-database might be updated, but the read-database is not.
5. Using a Message Queue and the Outbox Pattern
To prevent the write-database from getting out of sync, a message queue and the outbox pattern can be used as follows:
- The command updates the write-database and stores a message in the outbox table. By using the outbox pattern, consistency is ensured, which would not necessarily be the case if the command wrote directly to the queue.
- A worker continuously reads messages from the outbox table and publishes them to the message queue.
- Another worker consumes messages from the queue and updates the read-database.
- Optionally, the command can try to update the read-database directly; if it fails, the message queue ensures eventual consistency.
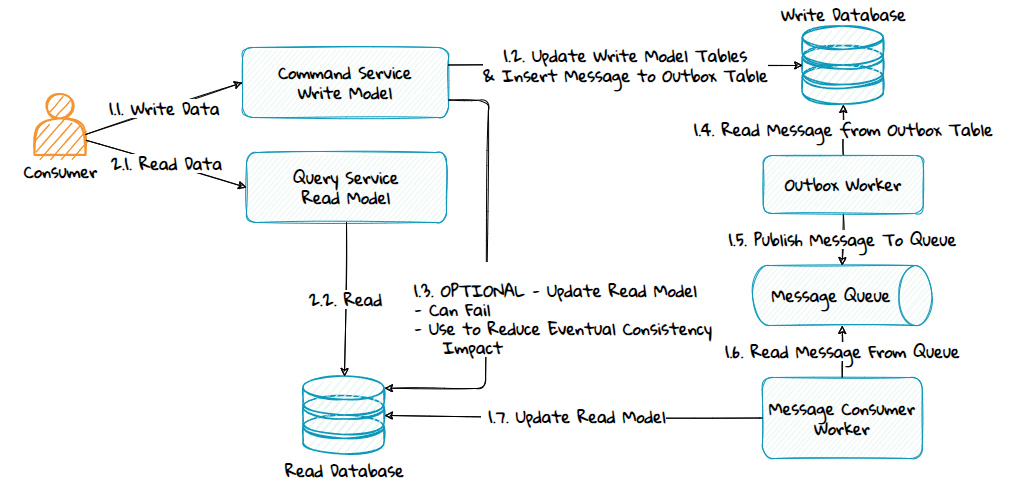
Advantages:
- Commands execute faster since read-database updates are offloaded to the message consumer worker.
- Guaranteed data consistency between the write and read models.
Disadvantages:
- The read-database will be eventually consistent, with some delay.
- More complex to implement and manage.
6. Using Change Data Capture (CDC)
As an alternative to messaging, Change Data Capture (CDC) can be used to synchronize the write- and read-database. This approach tracks changes to tables in the write-database, and a worker process updates the read-database. CDC isn't covered in detail here.
7. Event Sourcing
In traditional systems, the write-database stores only the current state. Event sourcing, however, stores all changes as a timestamped sequence of events. These events can be replayed to reconstruct the current state. For optimization, a snapshot can represent the current state at a specific time.
Event sourcing can use a RDBMS, document databases, or specialized event stores.
Event sourcing is not required for CQRS, but it often complements it. It's a big topic and won't be covered in further detail here.
Final Words
As with any architectural pattern, CQRS should be used with care. Ask yourself:
- Can simpler scaling methods achieve good enough performance?
If the answer is yes, avoid CQRS. If not, CQRS may be the solution you need.