
Scaling Microservices Part 5 - Data Replication Using Messaging
In monolithic systems with a single relational database, combining data from multiple tables can quickly be done using a SQL join. A join cannot be used in a microservice architecture if the same data is spread across multiple services and databases. Instead, one often ends up with a synchronous service call from one service to another to get the required data. If the system gets a high load or the data is designed or required in a way that many service calls to retrieve the data must be made, this can soon lead to performance issues. Many methods can be used to solve this, but in this part, we will see how data replication can be used. Data replication can be done using various ways, but we will focus on publish-subscribe realized through messaging.
The Example Case
Imagine an e-commerce system built up of a website with various underlying services: the Product Service is responsible for providing information about all the products sold, and the Order Service is responsible for storing orders and retrieving order details.
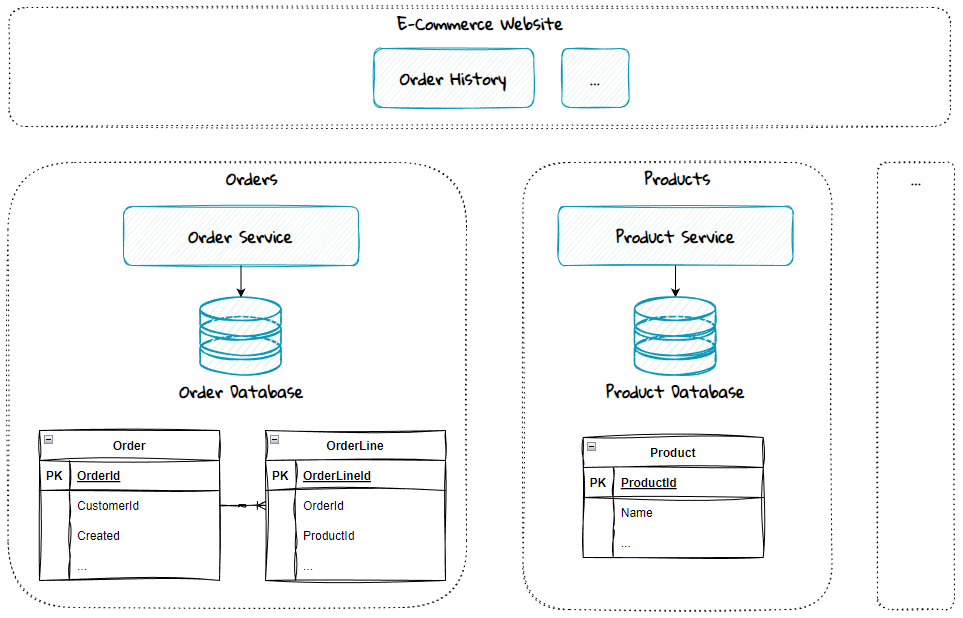
The website has an order history page where the customers can see their previous orders.

The product name is not stored in the Order database. Thus, the Order Service makes a synchronous call to the Product Service to retrieve this.
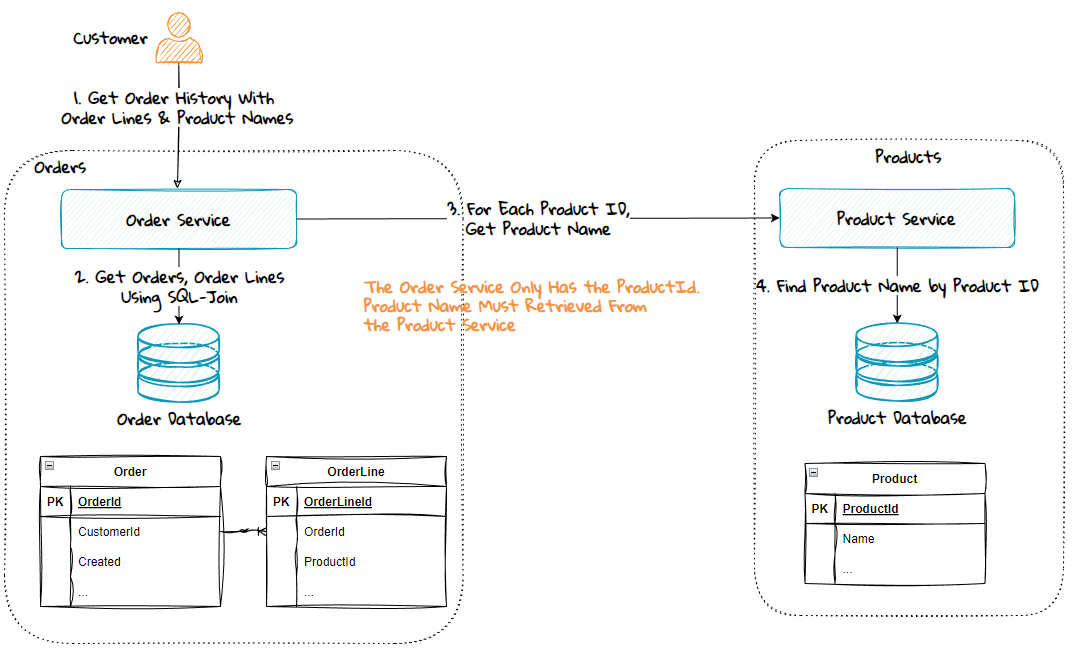
A synchronous service call has advantages and disadvantages.
Advantages:
- The Order service always gets the latest product name. There is no delay due to eventual consistency.
- A synchronous service call requires a few lines of code; it's easy to understand and maintain.
Disadvantages:
- The order history page is down if the Product Service is down.
- Service calls are slower than a local database call.
- More complex to test. If the tests depend on and make calls to a live Product Service, the tests might be brittle due to unstable endpoints or data that changes without notice.
Data Replication Enables SQL-Joins
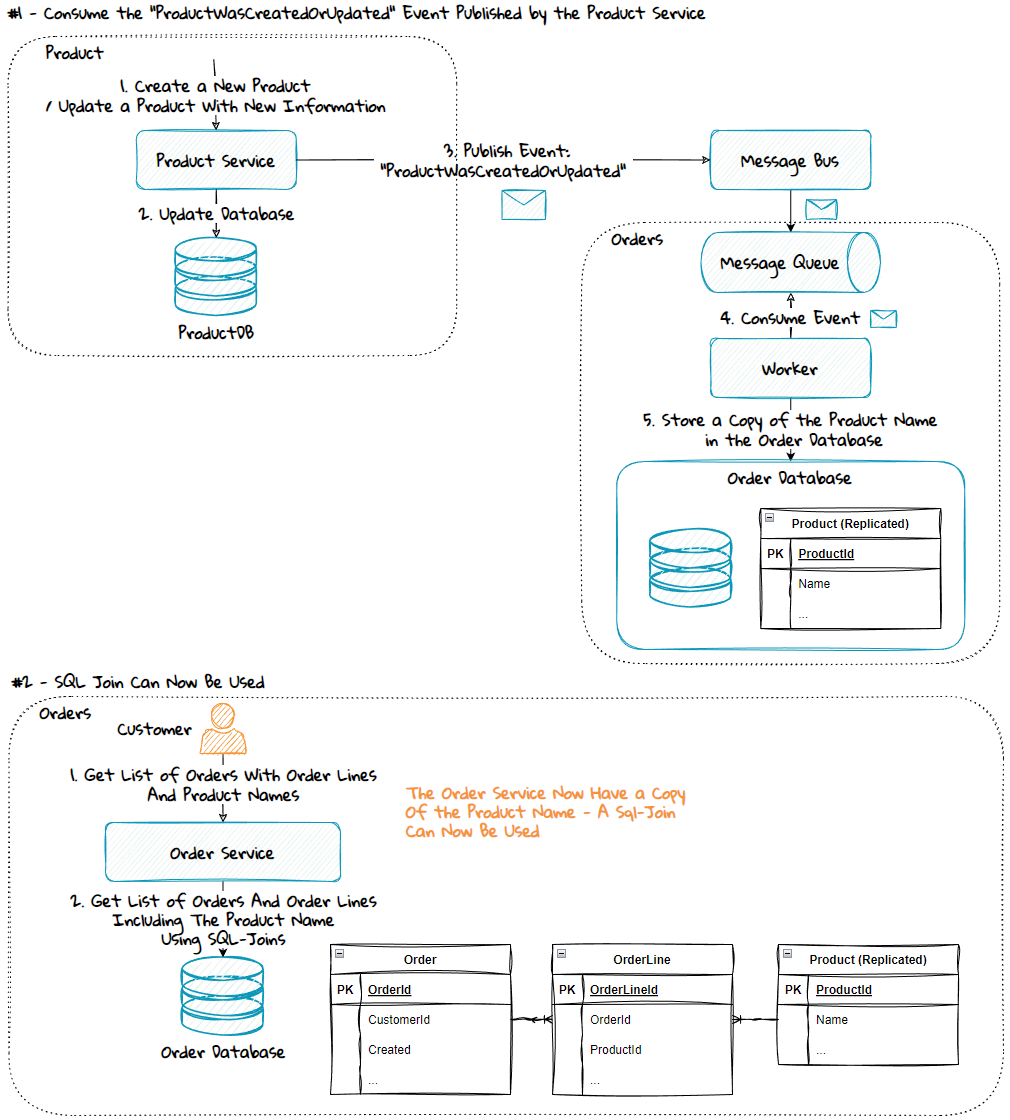
Another way to solve this is to replicate the product name from the Product Service to the Order Service. This can be done using messaging and publish-subscribe:
- When the Product Service receives a request to update the details for a given product, the Product database is first updated, then a “ProductWasCreatedOrUpdated” event is published.
- The Order Service subscribes to this event, and when it consumes it, it updates the Order database with a copy of the product information.
Since the Order Database now has a copy of the product name, the service can be modified to use an SQL-join instead of making a service call.
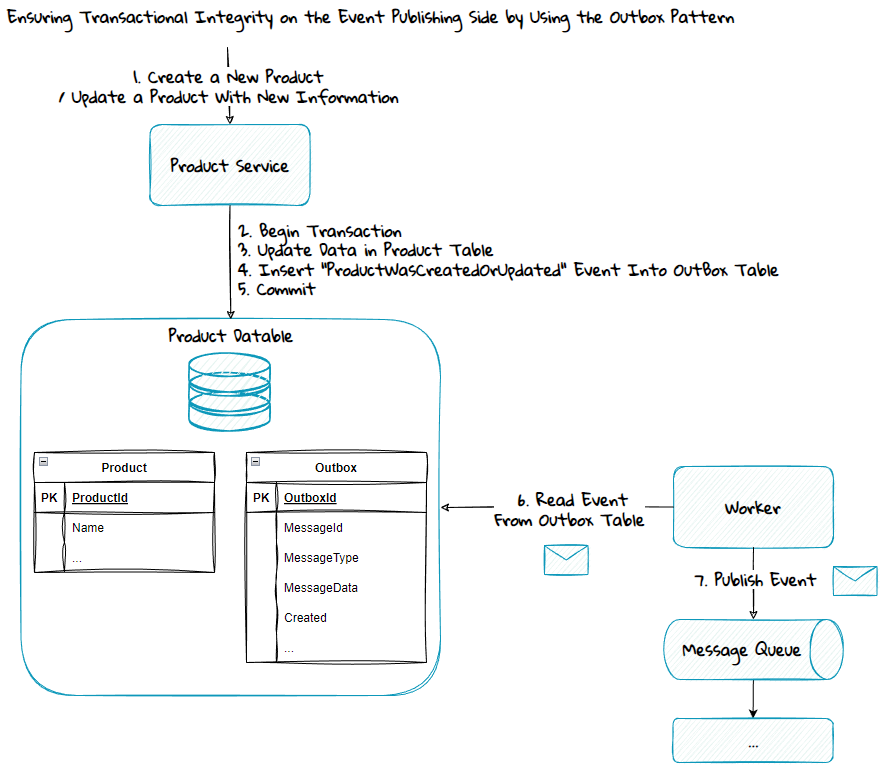
The event publishing in the diagram above is simplified. Suppose the update request to the Product Service is initiated by a process that does not guarantee a retry until both the database and the event has been successfully updated and published. In that case, the passport pattern must be used. Using the passport pattern guarantees transactional integrity through a single transaction against the database and temporarily storing the event in an Outbox table. A worker must then read the event from the Outbox table and publish it to the message queue.
As with every architectural pattern, data replication has advantages and disadvantages.
Advantages:
- The order history can be returned even if the Product Service is down.
- Better performance since querying the database is faster than making a service call.
-
Testing is simplified since the test verification process can be divided into two separate parts:
- Verify that the event is consumed and the database is updated correctly.
- Verify that the order history returns the correct data from the database. This is now easier to test since test data can be inserted into the Order database instead of having to fake/mock the Product Service.
- The dependency on the Product Service is changed from a tightly coupled, synchronous dependency to a more loosely coupled asynchronous message-based dependency.
Disadvantages:
- It's a much more complex solution.
- The code will be harder to reason about since it's spread across multiple components.
- It's subject to eventual consistency: Data will always be out of sync for a short time until the consumers have processed the event.
- Data can get out of sync for an extended period if publishing or consuming events fails.
- If you have a service, enforcing authorization rules on data items or item property levels is relatively easy. For events it's more complex since events don't contain any logic, only data, and they are sent to multiple consumers.
Master Data / Data Ownership
In any system, deciding and specifying which service owns what data is essential. This gets especially important when data are replicated to multiple databases because you don't want the same type of data to exist in different variants throughout the system.
Updating data must only be done through the service owning the data. In our example, the Product Service must be called if the product information data must be changed. The Product Service will then distribute these changes as events to the consumers.
Data Authorization
Many systems need to enforce multiple levels of authorization checks. When a service like a REST API is used, then it's straightforward to implement these checks:
- Verify that the consumer has access to the service operation. If it fails, return access is denied.
- Verify that the consumer can access the specific data item. Depending on their permissions, they might have access to all the items or just a subset. If it fails, return access is denied.
- Verify that the consumer has access to all the properties on a data item or just a subset of the properties. If only a subset, only return that subset of data.
When publish-subscribe is used, the first rule can be enforced when a service asks to consume a specific event type. The second and third rules pose a challenge to implement.
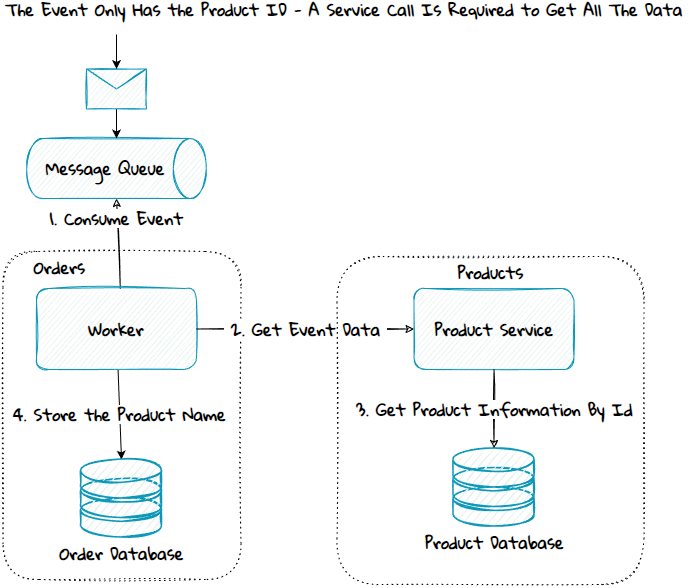
One way to solve it is to publish different events to different consumer groups. Another solution is to change the event only to include the ID for the created or modified item. A service must then be called to get data related to the ID.
The service operation can then enforce these rules:
- If the consumer is not allowed to access the data item, access denied can be returned, and the consumer can continue to process the next event.
- If the consumer has access to the data item, but only a subset of the properties, then only that subset of data will be returned.
A completely different solution would be to create a custom service that provides publish-subscribe functionality, such as a REST API. A relational database or similar can be used to store the events, and the service does the authorization checks and filtering for each authenticated consumer.
Handle Out of Sync Scenarios
Different error scenarios can happen that can make the data in the consumer get out of sync with the publisher:
- The publisher doesn't publish the events as promised.
- The publisher publishes events with incorrect data.
- The consumer worker is not running, so the events are not processed.
- The consumer can't process the event.
- The consumer code has errors, and the database gets updated with incorrect data.
Consumers need to have mechanisms in place to detect and reduce these errors:
- Logging with the right criticality and enough details.
- Monitor that all the components responsible for publishing and consuming the events are up and running.
- Data integrity verifications with a partial or a full resync if any error.
- Store the raw event data.
Resync Functionality
The consumer should store the raw event data in case a resync is needed. However, there might be times when these event data are invalid and cannot be used for resyncing. Due to this, the publisher should provide ways to do a resync:
- Partial, which the consumer uses if only a subset of the data is considered invalid and must be resynced. This is typically per item and can be realized by a service with a get-item-by-ID operation.
- Full, which you use if the entire dataset is invalid and must be resynced. A service, a message stream, or republishing all the events can be used to realize this.
Resync can be triggered manually or automatically:
- Manual trigger - if there is a risk that code on the consumer side has errors, it doesn't make sense to automatically trigger a new resync because the result would be the same. Instead, the error must be analyzed and fixed before a resync is manually triggered.
- Automatic trigger - if the error has been analyzed in the past and it's known that a resync will fix the problem, then a resync can be automatically triggered for these known errors.
Ensuring Data Integrity
To ensure the consumer is in sync with the publisher, you can run a full resync at given intervals, like once a month. Or you can automatically run verifications that trigger a resync if there is a data integrity error. Verifications can be done using various methods:
- The consumer can compare a random set of rows/items to the publisher. To be able to do this, the publisher needs to provide a service that can be called to retrieve the data or a message stream with all the data.
- The publisher can make snapshot data available on the published event or through a service. The snapshot data can contain the number of items in the dataset, the number of items within a given category, or a hash of the complete dataset.