
Scaling Microservices Part 2 - Caching
What Is Caching?
Caching is a technique where you store data that are slow to retrieve or compute, in a cache so that future requests are served faster.
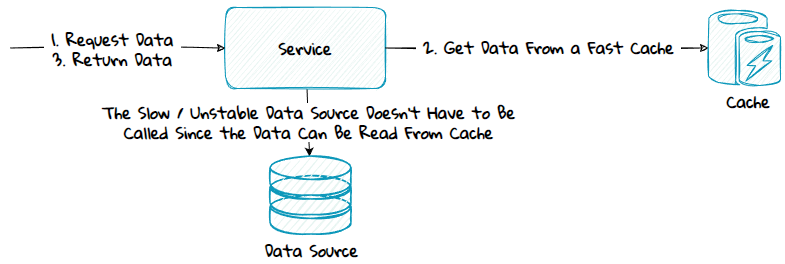
Data can be slow to retrieve because the service needs to:
- Call a service or database located somewhere with high network latency, for instance another datacenter or geographical location.
- Call a service that is unstable.
- Call a service or database that is poorly designed and not optimized for fast retrieval.
- Aggregate data from multiple data sources.
- Make complex, time-consuming computations.
The Advantages of Caching
Caching can help with the following:
- Improve the performance and stability of the system.
- Reduce load on the backend. If the data are cached in the frontend, the backend is never hit. Or if the data are cached in the backend, and data are retrieved from the cache instead of running through multiple tiers with complex code, database calls and service calls.
- Reduce infrastructure costs since scaling the caching infrastructure is often cheaper than scaling for instance a relational database to handle more reads.
- Relatively low effort to setup and implement compared to other scaling alternatives.
The Disadvantages of Caching
Caching has the following disadvantages:
- Keeping the cache up to date by removing or updating stale data can be difficult.
- Makes the system more complex by adding a caching layer where more things can go wrong.
- Can hide technical debt that should be fixed, such as data structures and service contracts that do not reflect the current state or need of the domain.
When to Use Caching
You want to consider using a cache when:
- The system is not as performant or stable as needed.
- The user base or traffic will continue to increase.
- It is cheaper to add a caching infrastructure than scaling the current infrastructure.
What to Cache
You want to consider caching data and files that are:
- Frequently used.
- Shared between all the users or many users.
- Read more often than updated, the read to write ratio should be high.
- Delivered by slow or unstable endpoints.
Cache Population
A cache can be populated in two ways, using lazy loading or preloading.
Lazy Loading
With lazy loading, you load the data into the cache if the data is not already there.
Advantages:
- The cache will be smaller in size since it will only be filled with data that are in use and requested.
Disadvantages:
- Get a performance penalty on the first request since the data won't exist in the cache.
- Higher chance of having stale data in the cache.
There are two patterns that can be used to lazy load the cache: read-aside and read-through.
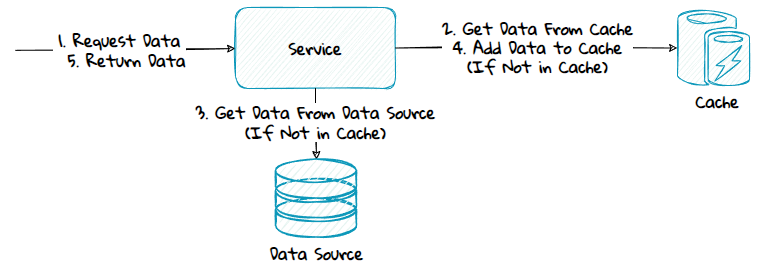
1) Read-Aside
When using this pattern, the application code is responsible for populating the cache.
Advantage:
- The code is simple to implement and reason about.
- The system can function even if the cache is down.
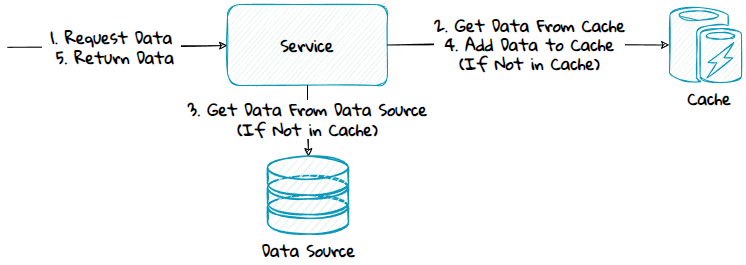
2) Read-Through
With this pattern, the cache is responsible for populating itself. This is done by configuring the cache and/or making a custom plugin for the cache that integrates with the underlying data sources.

Advantage:
- The application code is simplified since it will only integrate with the cache and not the data sources.
Disadvantages:
- Potential more complex and harder to reason about since the code of the system will be spread across multiple components, some will be in the application code and some in the cache.
- Get a stronger dependency on the cache provider.
Preloading
With preloading, the data is loaded into the cache in advance.
Advantages:
- All the requests, including the first, can use the cache.
- Gets more flexibility since the cache contains all the items and not just a subset, this can for instance allow for better performance when searching and filtering on the data.
Disadvantages:
- More complex and time-consuming to implement.
- The cache will contain more data, also data that might be infrequently requested.
- If the caching infrastructure is down, the entire system will be down unless read-aside is used against the preloaded cache.
A cache can be preloaded using different methods, which one to choose will depend on if the data source and the cache has the same service boundary or not.
Same service boundary:
- Write-Aside
- Write-Through
- Write-Behind
Different service boundary:
- Push-Based Model
- Pull-Based Model
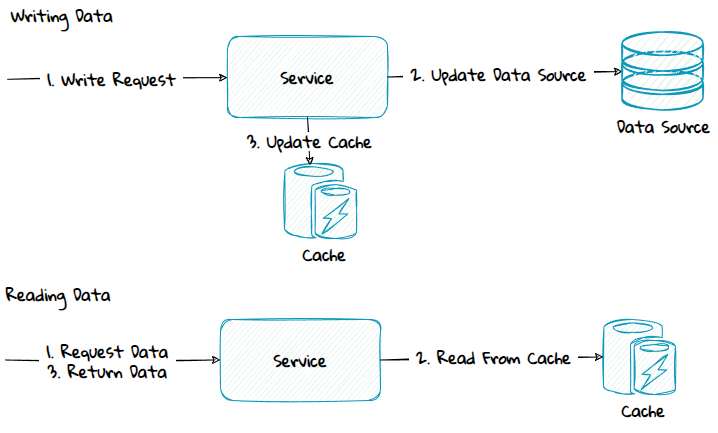
1) Same Service Boundary - Write-Aside
With write-aside, the application code first updates data in the data source, and then updates the cache.
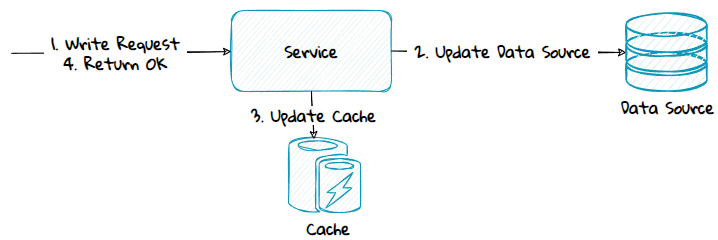
Advantage:
- Simple to implement and reason about.
- Lower coupling to the cache provider compared to the other methods.
Disadvantage:
- Data in the data source and cache can get inconsistent if updating the data source succeeds, but updating the cache fails.
The data inconsistency risk can be mitigated by using a message queue with or without the outbox-pattern:
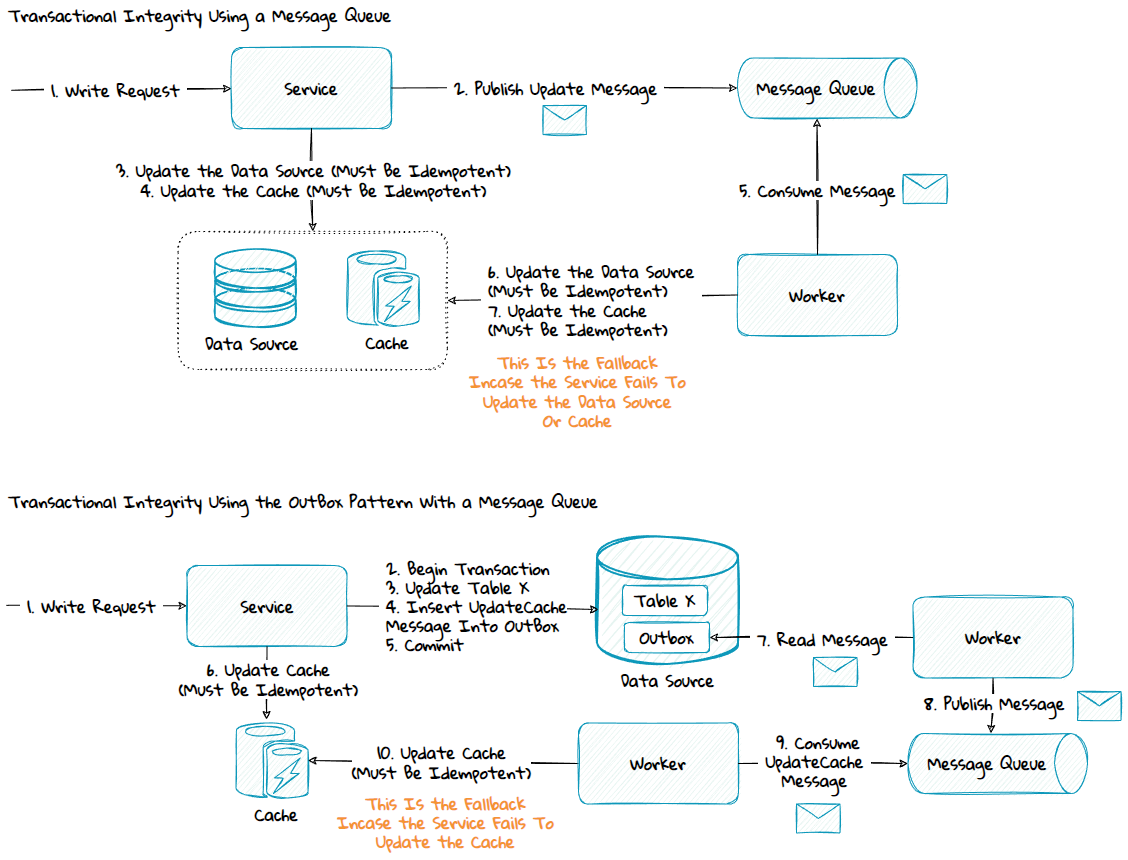
2) Same Service Boundary - Write-Through
With write-through, the application code updates the cache, and the cache synchronously updates the data source, before a persisted OK is returned.

Advantage:
- Reduces the need for complex transaction management since the service will only update the cache.
Disadvantage:
- Potential more complex and harder to reason about since the code of the system will be spread across multiple components, some will be in the application code and some in the cache.
- High coupling to the cache provider.
3) Same Service Boundary - Write-Behind
Write-behind is the same as write-through with the only difference being that the cache updates the data source asynchronously in the background. This means the cache is updated, but the data source is not updated when the cache returns OK.

Advantage:
- Fast, the cache will return persisted OK when it's persisted in the cache.
Disadvantage:
- Potential more complex and harder to reason about since the code of the system will be spread across multiple components, some will be in the application code and some in the cache.
- Need to have mechanism to deal with eventual consistency, where the cache and data source for a short time are not in sync. When persisted OK is returned to the client, the data source is not yet updated since this is done asynchronously in the background.
- High coupling to the cache provider.
4) Different Service Boundary - Push-Based Model
If the data source belong to a Service A, but Service B need to cache the data, a push-based model can be used. This can be done using publish-subscribe with messaging, streams or webhooks.
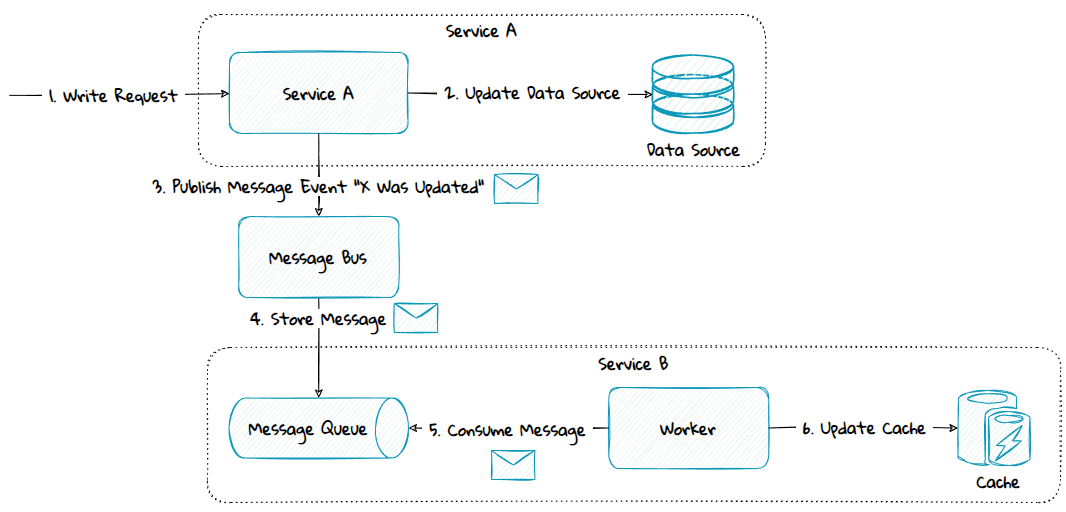
If messaging is used, then:
- The service B needing to cache data, will subscribe to the changes from the service A through its message bus.
- If any data are changed, Service A will push any changes as events via a message bus to Service B's message queue.
- Service B will read data from the message queue and use it to update the cache.
The diagram above is simplified to make it easier to understand. To preserve transactional integrity the outbox pattern should be used.
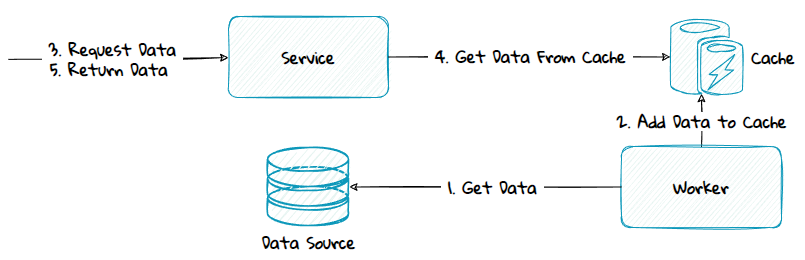
5) Different Service Boundary - Pull-Based Model
If publish-subscribe is not available to use, a pull-based model can be used instead. A worker will call the data source to get the data to cache. Depending on the API provided by the underlying data source, one or many calls must be made to retrieve all the data needed to populate the cache. And to keep the cache up to date this logic must be re-run at given intervals. Use this method only if preloading is necessary and the push-based model is not provided.
Cache Invalidation
There is a quote within computer science that says there are only two hard things in computer science: cache invalidation and naming things.
Cache invalidation can be difficult because you need to balance having stale objects with incorrect state in the cache vs frequently refreshing the cache with unchanged objects which gives a performance hit.
There are various methods to manage cache invalidation:
1) Write-Through / White-Behind
When Write-Through / Write-Behind is used, the cache is invalidated and kept up to date as soon at the data source is updated.
2) Time Based Invalidation
When time-based invalidation is used, the cached object is marked with a time to live/ expiration time. When this time is reached the object is automatically removed from cache.
It can be a good idea to have two expirations times to reduce potential downtime in situations when the data source is down:
- A soft expiration time stored on the cached object. When this time is reached, the system will call the data source to get the latest data to cache. If the data source is not responding, the old data from the cache is returned.
- A hard expiration time. When this time is reached, the object is automatically removed from the cache.
3) Cache Validation
With cache validation, the service caching the data will call the data source to get a version number or last modified date of the data and compare this to the version in cache, if there is a mismatch the new version must be retrieved from the data source. It only makes sense to use this method if the validation call is more lightweight than requesting the actual resource.
4) Cache Bypass
Another method is to bypass the cache completely. This can be done in various ways depending on the technology used.
This method is often used in frontend code to bypass the browser cache, to get the latest version of a static file. One way to do this is to add a unique parameter to the URL. The parameter value can be the version number of the frontend code, hash of the file content or a unique identifier. If "foo.com/site.css?10" is requested, the next time the file is changed and deployed, the frontend will request "foo.com/site.css?11".
5) Event Based Invalidation
Event based invalidation uses an event driven architecture to notify other systems of changes. This can be implemented using messaging with publish-subscribe, streaming or webhooks with custom callbacks.
If public-subscribe is used the flow would be:
- Service A will subscribe to changes from the slow service B through its message bus.
- If any data are changed, Service B will push any changes as events via a message bus to Service A's message queue.
- Service A will read data from the message queue and use it to update the cache.
Cache Eviction Policies
A cache eviction policy must be defined to tell the cache how to behave if the cache gets full. Any of the following policies can be used:
- Return an error without storing any new data items.
- Remove data items that are soon to expire.
- Remove data items that are least recently used.
- Remove data items that are least frequently used.
- Randomly remove data items.
Private Cache vs Shared Cache
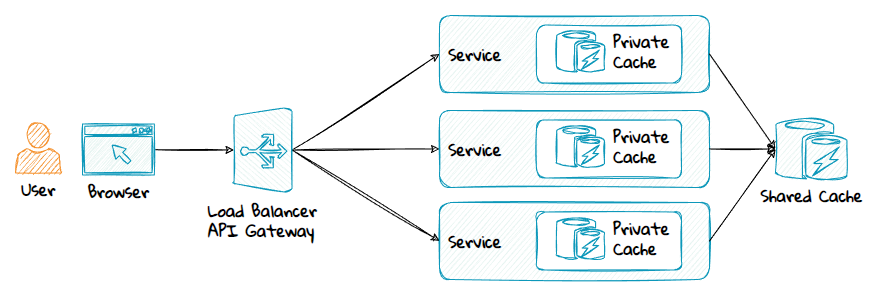
Private Cache
A private cache is a cache that exists inside a single instance, either in memory or as files on the disk.
Advantage:
- Very fast.
Disadvantages:
- Each instance needs to populate its own cache, this gives a performance overhead.
- Each instance might have a copy of the same data in the cache with different expiration times. When the data are changed, the instances will have a mix of new and old data in their cache until the expiration time for all the caches have been met. This can cause issues in some situations. For instance, if the frontend for a given user makes multiple calls to the same service but hit different instances, each having different versions of the data cached, which might result in wrong data returned or computed.
Shared Cache
A shared cache is a distributed cache that is shared between multiple service instances or services.
Advantages:
- Since the cache is shared between all the instances, any data put in the cache by one instance can be used by the other instances.
- All the instances will use the same version of the data.
Disadvantages:
- Slower than a private cache since a network call must be made.
Client-Side Cache vs Server-Side Cache
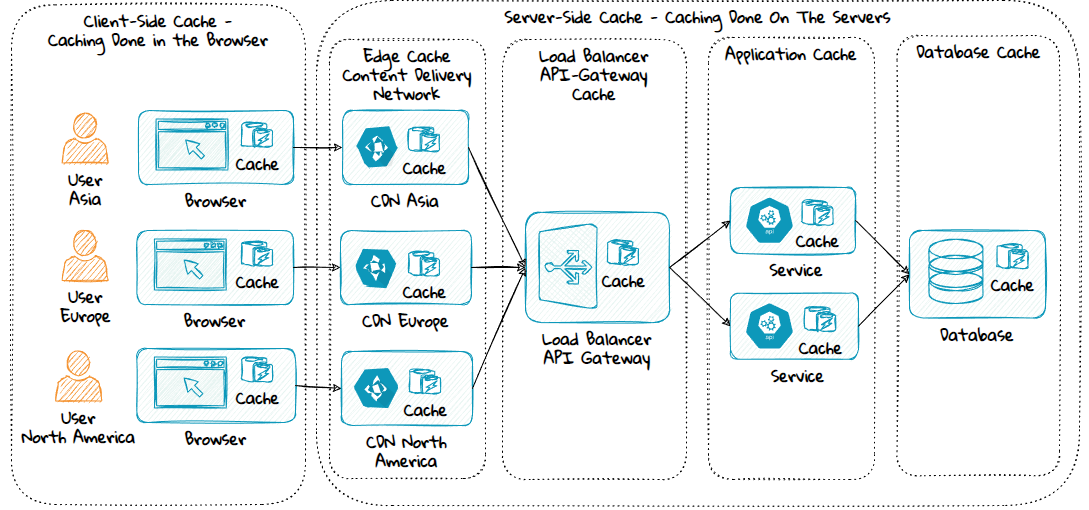
Client-Side Cache
A client-side cache is a private cache that exists on the client, typically a web browser. It can cache data and files requested from the server.
Use it to cache:
- Static files such as JavaScript, Stylesheets, Images.
- Data where risk of data manipulation or leakage is not a concern.
Advantages:
- It's fast.
- It reduces load on the server. If the data are cached on the client, the server doesn't have to be called.
Disadvantages:
- Data in the cache can be viewed and manipulated by the user.
- It can be hard to keep the cache up to data since the cache is not directly accessible by the backend / server-side process.
Server-Side Cache
A server-side cache is a cache that exists on the server, it can be a private-cache or a shared-cache.
Advantages:
- Cannot be viewed or manipulated by the user since it's hidden on the server.
- Easier to keep the cache up to date than a client-side cache.
Disadvantage:
- Slower than a client-side cache since one or more network calls must be made from the client.
Type of Server-Side Caches
1) Edge Cache
Many systems have users from various countries and continents. An edge cache can be used to improve the responsiveness of these systems by having a cache in different geographical regions. An example of an edge cache is Content Delivery Networks (CDN).
Typically used to cache:
- Public HTML-responses.
- Static files: JavaScript, Stylesheets, images, videos.
Advantages:
- Greatly reduces load on the backend infrastructure.
- Reduces the network latency for the user.
Disadvantages:
- Cache invalidation can be difficult.
- Risk of leaking private user data if used incorrectly.
2) Load Balancer Cache
The load balancer can cache the same content as an edge cache, but it has the disadvantage of usually not being geographically distributed. If used incorrectly, it risks leaking private data.
Use it if you don't have an edge cache.
3) API Gateway Cache
The API Gateway can be used to cache API-responses to improve the response times of commonly used APIs. It has the same disadvantages as caching in the load balancer.
Typically used to cache:
- API responses that are static or semi-static.
4) Application Cache
An application cache can be used in two ways:
- To cache the output of the application, the application can be a server-side frontend or service.
- To cache data needed within the application.
Typically used to cache:
- In a private in-memory cache: Static data shared between all users.
- In a shared cache like REDIS: Semi-static or dynamic data shared between all users, unique data for each user.
Advantages:
- Caching in this tier is more explicit than the higher tiers, you will see lines of code adding and removing data from the cache, making it easier to understand.
- This also means cache invalidation can be easier than in the higher tiers.
- Reduces load on the database and underlying service integrations.
Disadvantage:
- Not as performant as the higher tier.
Most caching should be done in this layer, and it should be done with explicit code that writes and reads to the cache.
5) Database Cache
In most cases you want to cache the result of SQL-queries in the application cache, like in a shared cache like REDIS. But sometimes it can make sense to have some dedicated columns or tables in the database used to cache values. For instance aggregated values, like the number of unread messages in a chat system.
Caching Strategy
If you want the best performance, you should cache data at the first tier that the request will hit because this reduces the number of tiers and components that must execute code. However, from a complexity view, it can often be easier and better to cache at the lowest tier that meets the performance needs. This can reduce complexity, make it easier to understand, and make cache invalidation simpler because it's done at the same level as the business logic is executed.
In many cases, multiple caching techniques, caching types, and caching at multiple tiers will be needed.
Cache Security
Limit What to Cache
You want to cache as little data as possible because:
- More data cached can affect the performance of the cache.
- Caching more data than needed means higher infrastructure costs.
- Caching data from external data sources might break with privacy regulations like the EU law General Data Protection Regulation (GDPR).
- In case of a data leakage, you want to expose as little data as possible.
Same Authorization Rules as the Data Source
Reading and writing data to the cache must be protected by the same authorization rules as the underlying data sources that the cached data is a product of. This is important because you need to prevent that:
- A person without access to the data in the underlying data sources, gets access to read the same data through the cache.
- An attacker without access to the data in the underlying data sources, gets access to change the same data in the cache and thus introduces a backdoor that bypasses important business or security rules.
There are various ways to protect against this, for instance:
- Services belonging to the same security context or group should have their own cache store instance, it should not be shared with services outside the security context.
- A shared cache store can be used by services across multiple security contexts or groups if the data in the cache are signed and encrypted. Signing the data will protect against unauthorized data manipulation, encryption will protect against any unauthorized personnel reading the data.
Deciding On a Cache Key
If you have multiple services using the same cache store, you need to make sure that you do not get a key collision through multiple services using the same cache key, but for different data. Use a key convention like the following to prevent this:
"{Area}_{Component}_{Functionality}_{Id}"
Caching Null Results
Sometimes you must integrate with a system that is extremely slow and where not all the users exist or have data. To prevent recurring lookup load for the users without data, use any of the following to cache that there are no data for the given user in the system:
- Add a flag "UserHasNoData" to the result class and add it to the cache for the given user.
- Cache an instance of a "UserHasNoDataInSystemX" class for the given user.