
Scaling Microservices Part 1 - Vertical and Horizontal Scaling
Performance issues and bottlenecks can sometimes be fixed by adding better hardware like a faster CPU, more memory, faster disk, or more disk space to the existing instances on which the microservices are running. This is known as scaling vertically or scaling up.
At some point, you might need more than this, you then need to add more instances to get the load distributed across multiple service instances. This is known as scaling horizontally or scaling out.
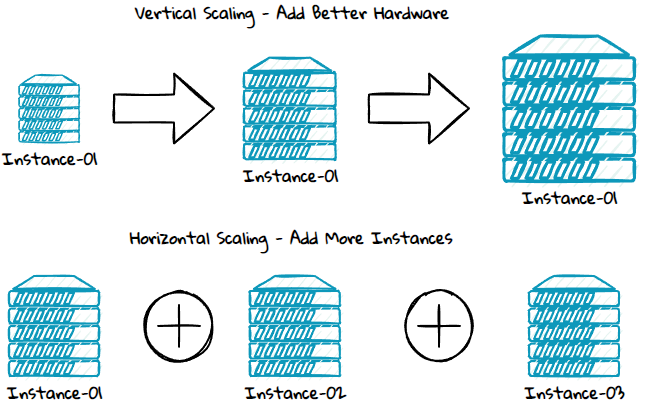
In a traditional monolithic architecture, the entire system needs to be scaled if you want to scale the system. With a microservice architecture, you can instead scale the single microservice with performance issues, which is simpler and more economical.
Most systems will use a combination of vertical and horizontal scaling. The size of each instance and the number of instances must be based on a cost and benefit analysis that considers things such as:
- Hardware costs - Scaling vertically can be cheaper.
- License costs - License models vary, some charges per instance, others per core.
- Operation costs - It's usually simpler and more cost-effective to manage fewer instances.
- Availability requirements - Having few instances will increase the risk for service downtime due to deployments, patching, etc.
The Advantage of Cloud Scaling
If your microservices are running in a cloud environment, then you have more flexibility and options on when and how you do the scaling:
- Ad hoc - If you notice any slowness, you can, through a script or a button click in the cloud provider dashboard, scale up or out.
- Time-based - If your service has less or more traffic during specific hours, for instance, low traffic outside regular working hours between 08.00-16.00, then the service can be configured to scale down after 16.00 and scale out again at 08.00.
- Automatic - Another option is configuring the service to scale automatically when the traffic increases. Just be aware that there is slowness to this, so it might not solve problems due to sudden traffic peaks.
More on Vertical Scaling
In most situations, it's straightforward to do vertical scaling by adding better hardware to the existing instances. However, it can become more complex if you want to perfect your code to run as efficiently and fast as possible on the available resources, such as running in parallel.
More on Horizontal Scaling
Horizontal scaling can be more complex than vertical scaling, but if you do it right, it can enable nearly infinite scale. We will go through how to scale the 2 most common component types horizontally:
- Service
- Database
Scaling Out a Service
There are at least two requirements to scale out a service from a single instance to multiple instances:
- You need a load balancer to distribute the traffic to the service instances.
- The service cannot use the memory of the instance it's running on to store the state. Instead, the service needs to be made stateless, or the state needs to be stored in shared storage, like a relational database or a NoSQL database like Redis.
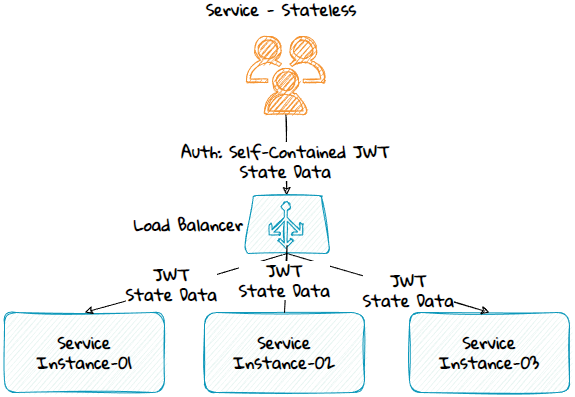
Stateless Service
A stateless service will get all the state information from the consumer, and the authentication will be typically done using a self-contained JSON Web Token (JWT).
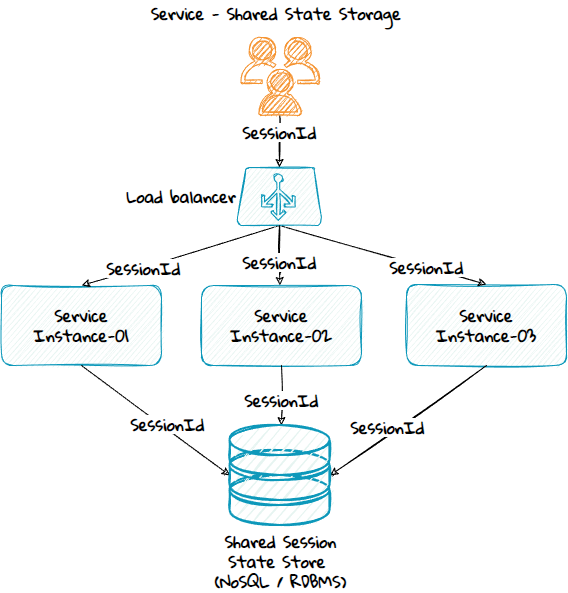
Service With a Shared State Storage
A service that uses shared state storage will use a relational database or a NoSQL database like Redis to store the state, and the consumer needs to pass along a Session Id for it to work.
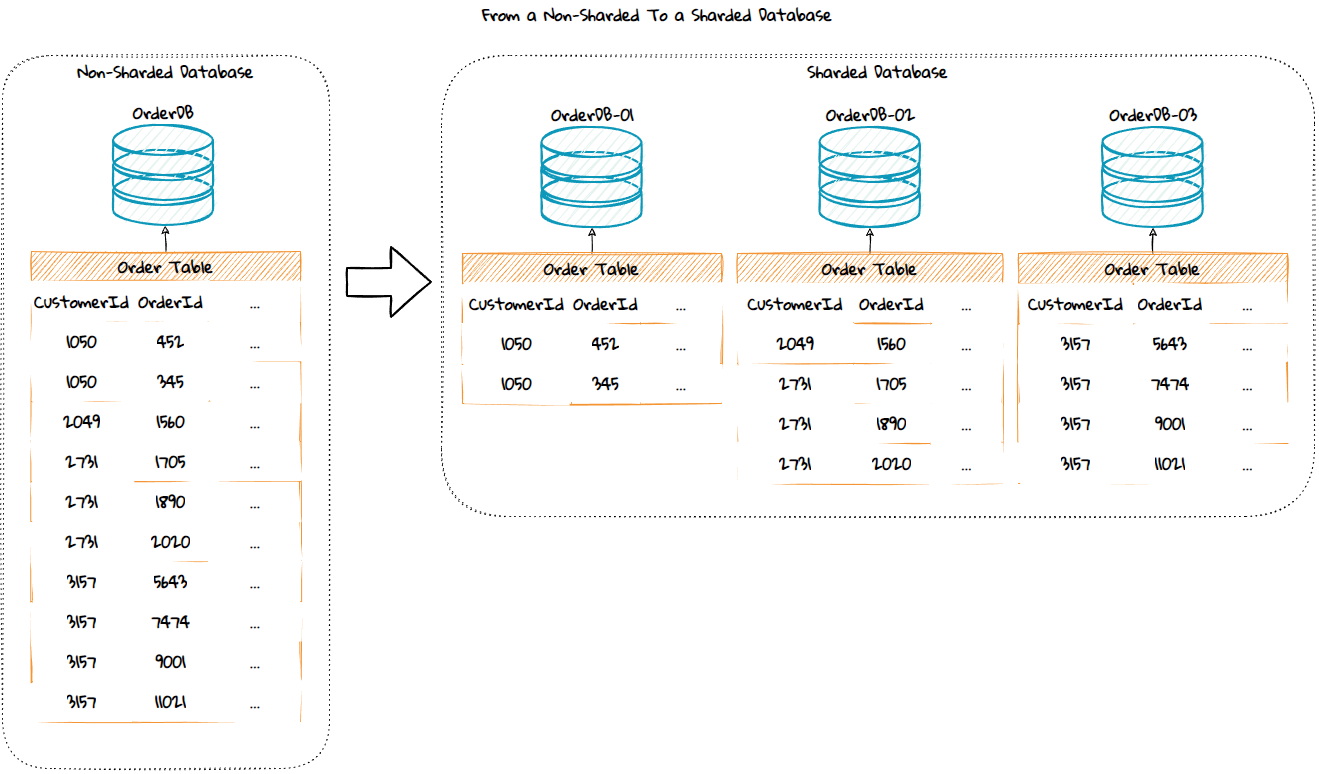
Scaling Out the Database
Database sharding can be used to scale out a database. This is a concept where rows from a table are distributed across multiple database instances that can be stored on different database servers. The databases will have the same database schema. This can give nearly infinite scalability and good performance since the rows in each table in each database are reduced.
Some NoSQL databases like Azure Cosmos DB support sharding out of the box, while typical relational databases like Microsoft SQL Server does not. If your database does not support it, you need to have a custom solution that uses a method to distribute the data across multiple shards. Some of these methods can be simpler, others can be more complex. Here are a few:
- Range function - This method is suitable if you have a customer table or similar with an auto-increment identity column. Then you can assign shards using from-to ranges:
- CustomerId from 1000 to 1999 = Shard-01
- CustomerId from 2000 to 2999 = Shard-02
- Etc.
- Hash function - If you do not have an auto-increment identity column but instead have a non-integer identifier such as a CustomerGuid, e-mail, etc., then you can use a hash function to assign a shard: ShardIndex = HashFunction(identifier) % NumberOfShards. Just make sure to use an identifier value that will never change.
- Directory-based sharding - This method can use either of the two methods above to get the initial shard index, you will also have a lookup table in a database where the shard index is stored. This method provides more flexibility, allows easy retrieval of the shard index, and makes it easier to change or update it later.
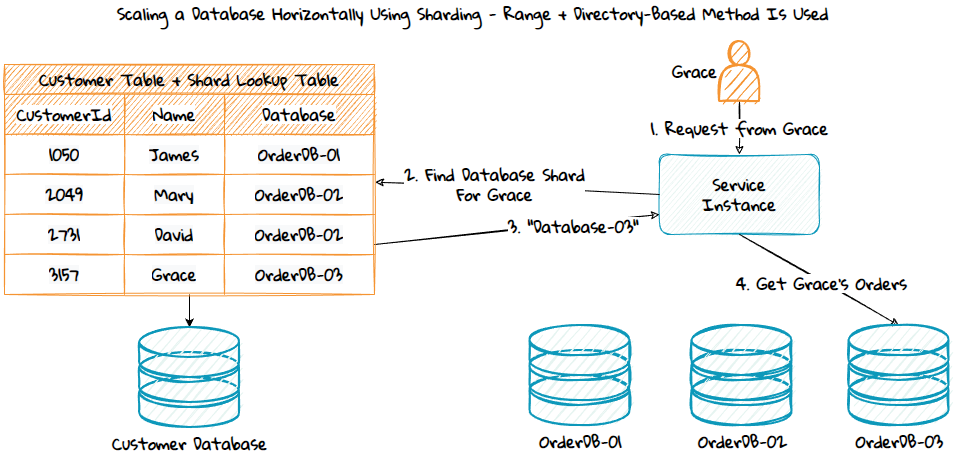
The downside of sharding is that join queries can only be executed against a single database. The right sharding key and method must be used to reduce the need to query for data in all the database shards. If a cross-database query is needed, techniques such as caching, data duplication, or an aggregation service that queries all the shards can be used. Other complexities must be considered and potentially managed:
- Evenly data distribution across shards. For instance, some customers might have 1 order, others might have 50 000.
- Automatically add more shards as the customer base increases.
- Move and redistribute data from one shard to another.
- Database migration to a new schema will be more time-consuming. To prevent more extended downtimes, you must ensure that your service will be backward compatible with the earlier database schema version. This can be solved by having a version table in the database that the code will check against to decide what version of the code to execute.